NOIP2016 普及组
T1:买铅笔
题目描述
P老师需要去商店买n支铅笔作为小朋友们参加NOIP的礼物。她发现商店一共有 种包装的铅笔,不同包装内的铅笔数量有可能不同,价格也有可能不同。为了公平起见,P老师决定只买同一种包装的铅笔。
商店不允许将铅笔的包装拆开,因此P老师可能需要购买超过支铅笔才够给小朋 友们发礼物。
现在P老师想知道,在商店每种包装的数量都足够的情况下,要买够至少支铅笔最少需要花费多少钱。
输入输出格式
输入格式
第一行包含一个正整数,表示需要的铅笔数量。
接下来三行,每行用个正整数描述一种包装的铅笔:其中第个整数表示这种 包装内铅笔的数量,第个整数表示这种包装的价格。
保证所有的个数都是不超过的正整数。
输出格式
个整数,表示P老师最少需要花费的钱。
输入输出样例
输入 #1
57
2 2
50 30
30 27
输出 #1
54
输入 #2
9998
128 233
128 2333
128 666
输出 #2
18407
输入 #3
9999
101 1111
1 9999
1111 9999
输入 #3
89991
说明
铅笔的三种包装分别是:
- 支装,价格为;
- 支装,价格为;
- 支装,价格为。
P老师需要购买至少支铅笔。
如果她选择购买第一种包装,那么她需要购买份,共计支,需要花费的钱为。
实际上,P老师会选择购买第三种包装,这样需要买份。虽然最后买到的铅笔数 量更多了,为支,但花费却减少为,比第一种少。
对于第二种包装,虽然每支铅笔的价格是最低的,但要够发必须买份,实际的花费达到了 ,因此P老师也不会选择。
所以最后输出的答案是。
【子任务】
子任务会给出部分测试数据的特点。如果你在解决题目中遇到了困难,可以尝试 只解决一部分测试数据。
每个测试点的数据规模及特点如下表:
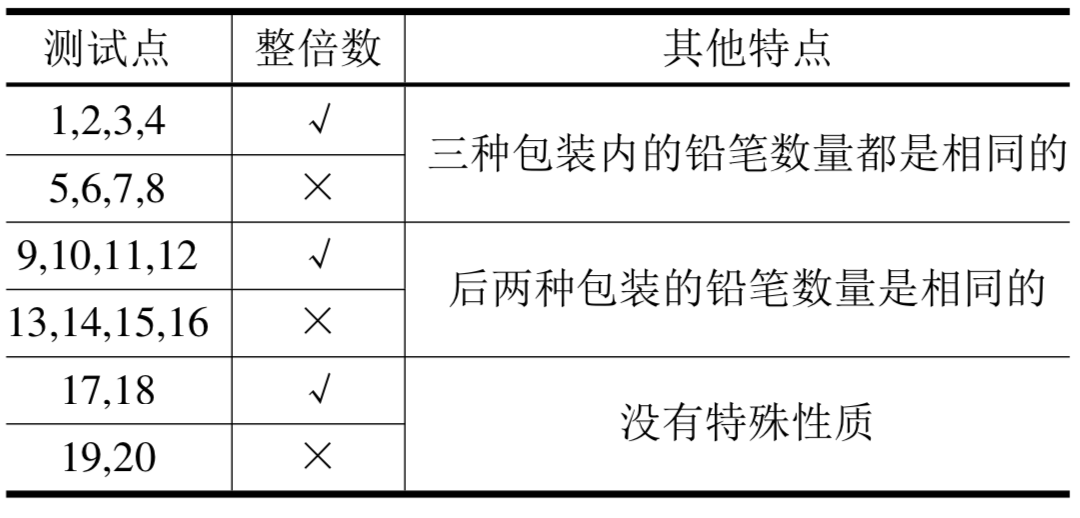
上表中“整倍数”的意义为:若为,表示对应数据所需要的铅笔数量—定是每种包装铅笔数量的整倍数(这意味着一定可以不用多买铅笔)。
题解:
本题直接模拟就可以。
读入每支铅笔的数量与价格,如果购买的数量 数量 的话,ans = min(ans, n / number * money)。
如果购买的数量 数量 的 话,ans = min(ans, (n / number + 1) * money)。
最后,输出 就OK啦!
#include <iostream>
using namespace std;
int main() {
int n, ans = 0xfffffff;
cin >> n;
for (int i = 1; i <= 3; i++) {
int number, money; //这种铅笔的数量与铅笔的价格
cin >> number >> money;
if (n % number == 0)
ans = min(ans, n / number * money);
else
ans = min(ans, (n / number + 1) * money);
}
cout << ans << endl;
return 0;
}
T2:回文日期
题目描述
在日常生活中,通过年、月、日这三个要素可以表示出一个唯一确定的日期。
牛牛习惯用位数字表示一个日期,其中,前位代表年份,接下来位代表月份,最后位代表日期。显然:一个日期只有一种表示方法,而两个不同的日期的表示方法不会相同。
牛牛认为,一个日期是回文的,当且仅当表示这个日期的8位数字是回文的。现在,牛牛想知道:在他指定的两个日期之间包含这两个日期本身),有多少个真实存在的日期是回文的。
一个位数字是回文的,当且仅当对于所有的从左向右数的第i个数字和第个数字(即从右向左数的第个数字)是相同的。
例如:
•对于2016年11月19日,用位数字表示,它不是回文的。
•对于2010年1月2日,用位数字表示,它是回文的。
•对于2010年10月2日,用位数字表示,它不是回文的。
每一年中都有个月份:
其中,月每个月有天;月每个月有天;而对于月,闰年时有天,平年时有天。
一个年份是闰年当且仅当它满足下列两种情况其中的一种:
1.这个年份是的整数倍,但不是的整数倍;
2.这个年份是的整数倍。
例如:
•以下几个年份都是闰年:。
•以下几个年份是平年:。
输入输出格式
输入格式
两行,每行包括一个位数字。
第一行表示牛牛指定的起始日期。
第二行表示牛牛指定的终止日期。
保证和都是真实存在的日期,且年份部分一定为位数字,且首位数字不为。
保证—定不晚于。
输出格式
一个整数,表示在和之间,有多少个日期是回文的。
输入输出样例
输入样例#1
20110101
20111231
输出样例#1
1
输入样例#2
20000101
20101231
输出样例#2
2
说明
【样例说明】
对于样例1,符合条件的日期是。
对于样例2,符合条件的日期是和。
【子任务】
对于的数据,满足。
题解:
本题是一个字符串问题。
依次读入起始日期 与终止日期 ,然后,枚举年 、月 与日 ,然后, 赋值为 , 赋值为 , 赋值为 。
首先,枚举月与日到次年的 1 月 1 日,然后,将 再枚举到 。最后,再次枚举月与日从终止年年的 1 月 1 日枚举到终止年的 月与 日,然后判断是不是回文日期。
那么,如何判断是不是回文日期呢?无疑,将年月日看作一个八位数字,如果第一位等于最后一位,第二位等于倒数第二位,第三位等于倒数第三位,第四位等于倒数第四位的话那么这个日期便是一个回文日期,也就是 year / 1000 == day % 10 && (year - year / 1000 * 1000) / 100 == day / 10 && (year % 100 - year % 10) / 10 == month % 10 && year % 10 == month /10 。
最后,输出回文日期总数就可以啦!
#include <cstring>
#include <iostream>
using namespace std;
int days[13] = {0, 31, 0, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
void leap(int n) { //判断是不是闰年
if ((n % 4 == 0 && n % 100 != 0) || n % 400 == 0) //是闰年
days[2] = 29;
else //是平年
days[2] = 28;
}
bool judge (int year, int month, int day) { //判断是不是回文日期
if (year / 1000 == day % 10 && (year - year / 1000 * 1000) / 100 == day / 10 && (year % 100 - year % 10) / 10 == month % 10 && year % 10 == month /10)
return true;
return false;
}
int main() {
int start, end;
cin >> start >> end;
int year = start / 10000, month = (start % 10000) / 100, day = start % 100;
leap(year);
int ans = 0;
for (int i = day; i <= days[month]; i++)
ans += judge(year, month, i);
month++;
day = 1;
for (int i = month; i <= 12; i++)
for (int j = 1; j <= days[i]; j++)
ans += judge(year, i, j);
year++;
month = day = 1;
while (year < end / 10000) { //枚举年份
leap(year);
for (int i = 1; i <= 12; i++)
for (int j = 1; j <= days[i]; j++)
ans += judge(year, i, j);
year++;
}
leap(year);
for (int i = 1; i < (end % 10000) / 100; i++)
for (int j = 1; j <= days[i]; j++)
ans += judge(year, i, j);
for (int i = 1; i <= end % 100; i++)
ans += judge(year, (end % 10000) / 100, i);
cout << ans << endl;
return 0;
}
T3:海港
题目描述
小K是一个海港的海关工作人员,每天都有许多船只到达海港,船上通常有很多来自不同国家的乘客。
小K对这些到达海港的船只非常感兴趣,他按照时间记录下了到达海港的每一艘船只情况;对于第i艘到达的船,他记录了这艘船到达的时间ti (单位:秒),船上的乘 客数,以及每名乘客的国籍 。
小K统计了艘船的信息,希望你帮忙计算出以每一艘船到达时间为止的小时(小时=秒)内所有乘船到达的乘客来自多少个不同的国家。
形式化地讲,你需要计算条信息。对于输出的第条信息,你需要统计满足的船只,在所有的中,总共有多少个不同的数。
输入输出格式
输入格式 第一行输入一个正整数,表示小K统计了艘船的信息。
接下来行,每行描述一艘船的信息:前两个整数和分别表示这艘船到达海港的时间和船上的乘客数量,接下来个整数表示船上乘客的国籍。
保证输入的是递增的,单位是秒;表示从小K第一次上班开始计时,这艘船在第秒到达海港。
保证 , ,, 。
其中表示所有的的和。
输出格式 输出行,第行输出一个整数表示第艘船到达后的统计信息。
输入输出样例
输入样例#1
3
144122
2223
1013
输出样例#1
3
4
4
输入样例#2
4
1 4 1 2 2 3
3 2 2 3
86401 2 3 4
86402 1 5
输出样例#2
3
3
3
4
说明
【样例解释1】
第一艘船在第秒到达海港,最近小时到达的船是第一艘船,共有个乘客,分别是来自国家,共来自个不同的国家;
第二艘船在第秒到达海港,最近小时到达的船是第一艘船和第二艘船,共有个乘客,分别是来自国家,共来自个不同的国家;
第三艘船在第秒到达海港,最近小时到达的船是第一艘船、第二艘船和第三艘船,共有个乘客,分别是来自国家,共来自4个不同的国家。
【样例解释2】
第一艘船在第秒到达海港,最近小时到达的船是第一艘船,共有个乘客,分别是来自国家,共来自个不同的国家。
第二艘船在第秒到达海港,最近小时到达的船是第一艘船和第二艘船,共有个乘客,分别是来自国家,共来自个不同的国家。
第三艘船在第秒到达海港,最近小时到达的船是第二艘船和第三艘船,共有个乘客,分别是来自国家,共来自个不同的国家。
第四艘船在第秒到达海港,最近小时到达的船是第二艘船、第三艘船和第四艘船,共有个乘客,分别是来自国家,共来自个不同的国家。
【数据范围】
题解:
由于 ,所以我们可以按人头来存储。
我们读入每艘船到达海港的时间和船上的乘客数量。然后依次每句每一个乘客的国籍 ,并将 赋值为时间 。用 数组存储每个乘客的国籍,然后将此乘客所属的国家 加一。若 为 的话那么 便加 。
然后我们枚举时间,如果 减去 的话,那么便代表这个乘客的时间超过一天了,因此便将这个乘客的信息全部删除。再特判一下,如果 的话,那么 便减 。最后,输出 便可以了!
#include <iostream>
using namespace std;
int passenger[300001][3], bucket[100001];
int main() {
int n, p = 1, start = 1, ans = 0;
cin >> n;
for (int i = 1; i <= n; i++) {
int t, k;
cin >> t >> k;
for (int j = 1; j <= k; j++) {
cin >> passenger[p][1];
passenger[p][2] = t;
bucket[passenger[p][1]]++;
if (bucket[passenger[p][1]] == 1) //第一个被加进来的
ans++;
p++;
}
for (int i = start; i <= t; i++) {
if (t - passenger[i][2] >= 86400) { //超出这个时间了
if (bucket[passenger[i][1]] > 0) {
bucket[passenger[i][1]]--;
if (bucket[passenger[i][1]] == 0)
ans--;
start++;
}
} else {
break;
}
}
cout << ans << endl;
}
return 0;
}
T4:魔法阵
题目描述
六十年一次的魔法战争就要开始了,大魔法师准备从附近的魔法场中汲取魔法能量。
大魔法师有个魔法物品,编号分别为。每个物品具有一个魔法值,我们用表示编号为i的物品的魔法值。每个魔法值Xi是不超过n的正整数,可能有多个物品的魔法值相同。
大魔法师认为,当且仅当四个编号为的魔法物品满足,并且时,这四个魔法物品形成了一个魔法阵,他称这四个魔法物品分别为这个魔法阵的物品,物品,物品,物品。
现在,大魔法师想要知道,对于每个魔法物品,作为某个魔法阵的物品出现的次数,作为物品的次数,作为物品的次数,和作为物品的次数。
输入格式
第一行包含两个空格隔开的正整数。
接下来行,每行一个正整数,第行的正整数表示,即编号为的物品的魔法值。
保证,,。每个是分别在合法范围内等概率随机生成的。
输出格式
共行,每行个整数。第行的个整数依次表示编号为的物品作 为物品分别出现的次数。
保证标准输出中的每个数都不会超过。每行相邻的两个数之间用恰好一个空格隔开。
输入输出样例
输入样例#1
30 8
1
24
7
28
5
29
26
24
输出样例#1
4 0 0 0
0 0 1 0
0 2 0 0
0 0 1 1
1 3 0 0
0 0 0 2
0 0 2 2
0 0 1 0
输入样例#2
15 15
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
输出样例#2
5 0 0 0
4 0 0 0
3 5 0 0
2 4 0 0
1 3 0 0
0 2 0 0
0 1 0 0
0 0 0 0
0 0 0 0
0 0 1 0
0 0 2 1
0 0 3 2
0 0 4 3
0 0 5 4
0 0 0 5
说明/提示
【样例解释1】
共有个魔法阵,分别为:
物品,其魔法值分别为;
物品,其魔法值分别为;
物品,其魔法值分别为;
物品,其魔法值分别为;
物品,其魔法值分别为。
以物品为例,它作为物品出现了次,作为物品出现了次,没有作为物品或者物品出现,所以这一行输出的四个数依次为。
此外,如果我们将输出看作一个行列的矩阵,那么每一列上的个数之和都应等于魔法阵的总数。所以,如果你的输出不满足这个性质,那么这个输出一定不正确。你可以通过这个性质在一定程度上检查你的输出的正确性。
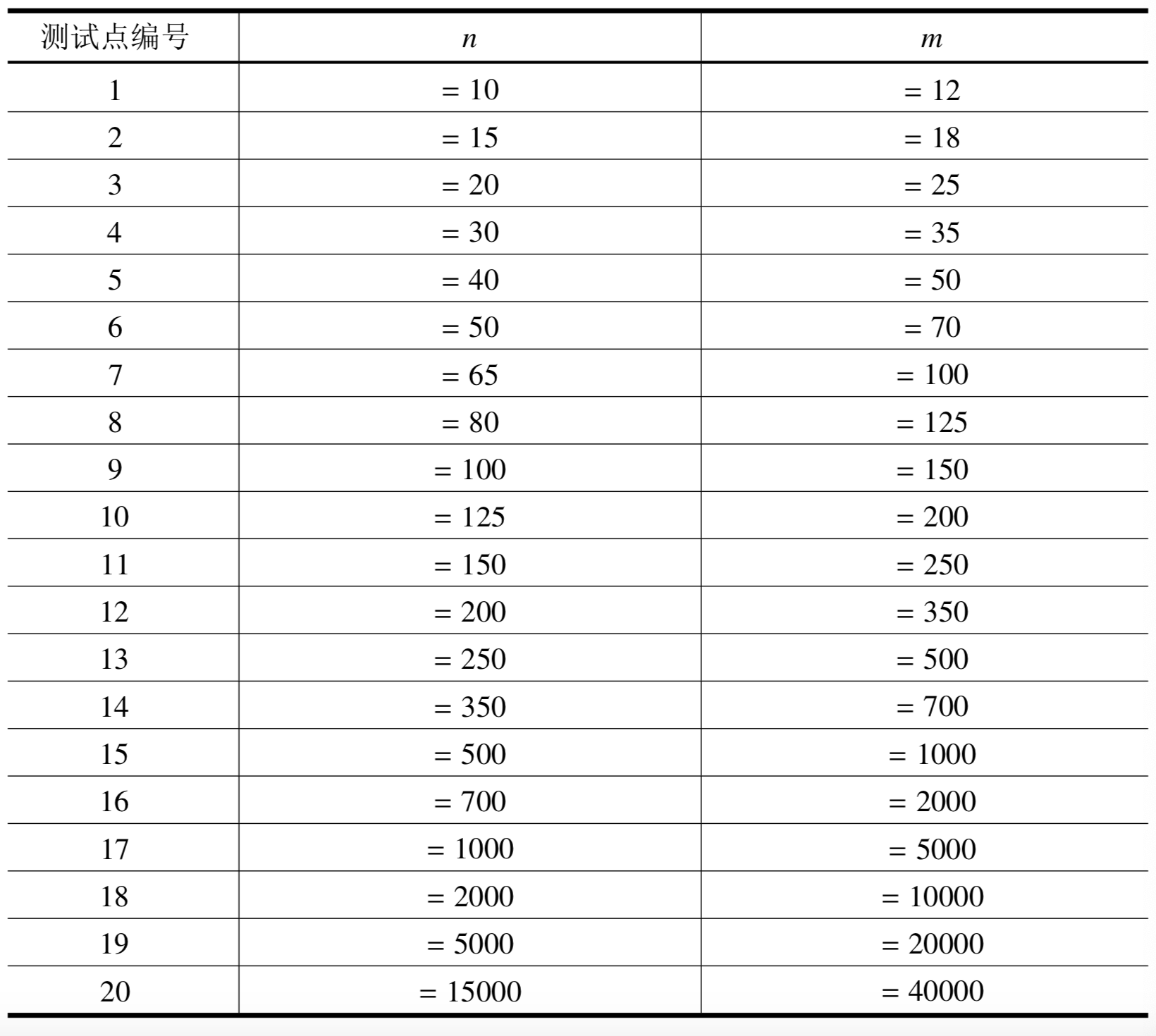
【数据规模】
占坑待填。。。